Extract Text From PDF Python
A Python library enabling developers to effortlessly retrieve textual data from PDF documents
Operating system: Windows
Publisher: Extract Text From PDF Python Tech Team
Release : Extract Text From PDF Python 2023.8.6
Antivirus check: passed
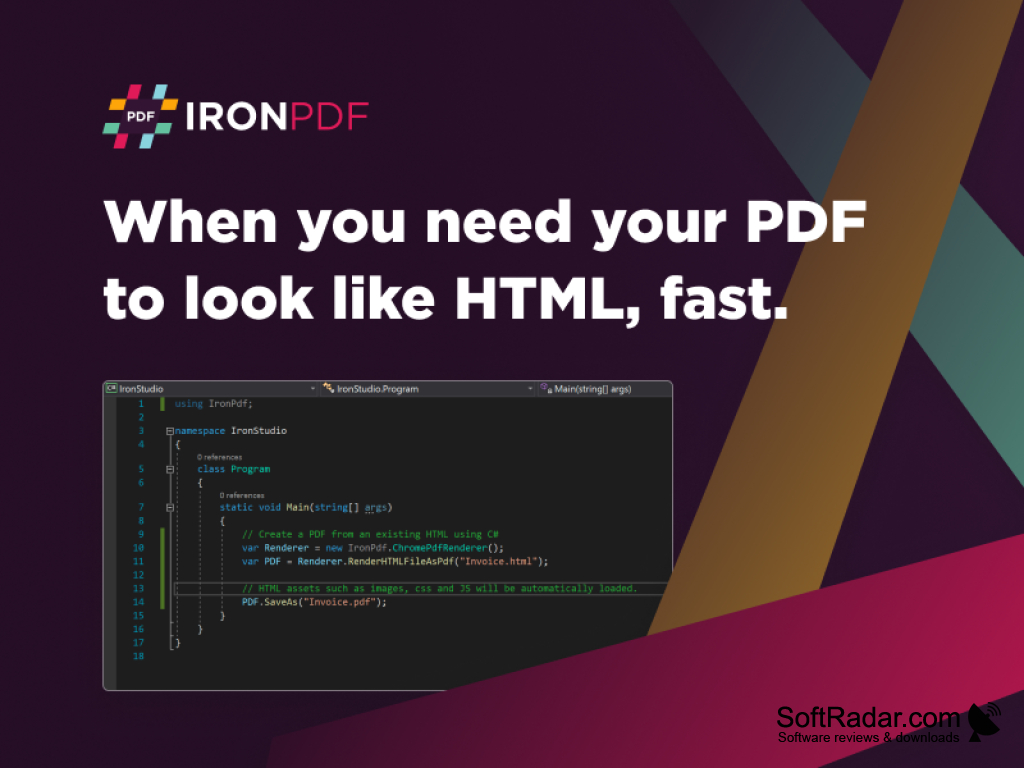
The 'Extract Text From PDF Python' tool is a powerful software based on a Python library, designed to efficiently retrieve text content from PDF files. It provides developers with an intuitive interface featuring several APIs and functions. With this tool, developers are able to open a PDF file, navigate through its pages, and extract text data using the Python library.
Using 'Extract Text From PDF Python', developers don't have to worry about the complexity of PDF parsing. The software takes care of all these intricacies, thus allowing the developers to focus on analyzing the extracted text and utilizing the data. The extracted content can be used for various tasks, including keyword extraction, sentiment analysis, text summarizing, and much more.
Features:- Granular text extraction: It allows text extraction at a detailed level, while maintaining the original structure and formatting of the document. This is particularly helpful when working with complex PDFs containing tables, footnotes, and other delicate textual elements.
- Easy integration: Integrating the Python PDF library into a Python application is a straightforward process. Developers can install the library using popular package managers like pip, import it into their Python script, and use its functions to extract text from PDF files.
- Comprehensive documentation: The library comes with detailed documentation and examples that aid developers in understanding and effectively implementing the text extraction process.
Therefore, 'Extract Text From PDF Python' is a powerful tool for all developers who need to extract text content from a PDF file. Its intuitive interface with user-friendly APIs and functions, simplified approach to PDF parsing, and ability to maintain the original document structure make it a popular choice among Python developers. Moreover, with comprehensive documentation at hand, even beginners will find it easy to get the hang of this software.
'Extract Text From PDF Python' simplifies the complex process of PDF text extraction for swift data utilization.
Requires installation of specific Python library for PDF parsing.
Requires a PDF viewer for manual file inspection.
PROS
Easy integration into Python applications.
Comprehensive documentation and user-friendly API.
CONS
Not very effective with multi-column PDF layouts.
Struggles with complex PDF structures and formatting.